cloudfit-public-docs
Python Asyncio Part 1 – Basic Concepts and Patterns
Since it was introduced in Python version 3.5 the asyncio library has caused a lot of confusion amongst programmers. Even with its significant improvements in Python 3.6 and its continuing evolution in 3.7 and 3.8 the library is still widely misunderstood and frequently misused.
Something that doesn’t help is that the official documentation for the library at Python.org, whilst extremely detailed and accurate, is not exactly easily followed, especially for a programmer with little previous experience of Python async programming.
When I started using asyncio in my work as part of BBC R&D’s cloudfit project I found that there were not many useful tutorials available online for me which helped me understand how to use asyncio well. In particular whilst there were a number of very elementary tutorials which introduced some of the basic syntax there were none I could find which were aimed at experienced Python programmers and filled the gap between the simple tutorials and the full library documentation.
This series of posts is intended to fill that gap.
This Post
This post is going to go over the basic concepts behind asyncio without going into implementation details. Some readers will already know this, some won’t. How to actually use asyncio in Python will be covered in the following posts in the series, but it’s important to have a good conceptual understanding before jumping into the details.
This post has the least code examples of any in the series, but I’ve tried to make up for that with illustrative diagrams.
Doing things one at a time, but out of order
I find that when introducing asyncio it’s important to explain what it is for, and more importantly what it isn’t for.
Traditionally computers have been machines that do one thing at a time. Modern computers (as of 2020) can often do multiple things at once, because they are equipped with a multitude of cpu cores, and whilst I cannot predict the future I expect that to continue to be true for at least the immediate future. And there are many books and many articles out there about how to make use of any number of libraries and frameworks designed to do multiple things at once by utilising multiple execution threads.
Asyncio is not one of these
Using asyncio in your Python code will not make your code multithreaded. It will not cause multiple Python instructions to be executed at once, and it will not in any way allow you to sidestep the so-called “global interpreter lock”.
That’s just not what asyncio is for.
TERMINOLOGY: Some processes are CPU-bound: they consist of a series of instructions which need to be executed one after another until the result has been computed. All of the time they are running is time that they are making full use of the computer’s facilities (give or take).
Other processes, however, are IO-bound: they spend a lot of time sending and receiving data from external devices or processes, and hence often need to start an operation and then wait for it to complete before carrying on. During the waiting they aren’t doing very much.
When a program is running IO-bound code it’s pretty common for the CPU to spend a lot of time doing nothing at all because the one thing that’s currently being done is waiting for something elsewhere.
It’s also pretty common to find that your program has a variety of other work it could be getting on with whilst this waiting is occurring, work which doesn’t depend upon the thing being waited for. So asyncio is designed to allow you to structure your code so that when one piece of linear single-threaded code (called a “coroutine”) is waiting for something to happen another can take over and use the CPU.
It’s not about using multiple cores, it’s about using a single core more efficiently
Subroutines vs. Coroutines
Abstractly most programming languages have methods which follow what is called the “subroutine” calling model. In this model of calling each time a function is called execution moves to the start of that function, then continues until it reaches the end of that function (or a return statement), at which point execution moves back to the point immediately after the function call, any later calls to the function are independent calls which start again at the beginning.
However there is an alternative model of code execution called the “coroutine” calling model. In this calling model there is a new way for the method (called a coroutine) to move execution back to the caller: instead of returning it can “yield” control. When the coroutine “yields” execution moves back to the point immediately after it was called, but future calls to the coroutine do not start again at the beginning, instead they continue from where the execution left off most recently. This way control can bounce back and forth between the calling code and the coroutine code, as illustrated in the following diagram:
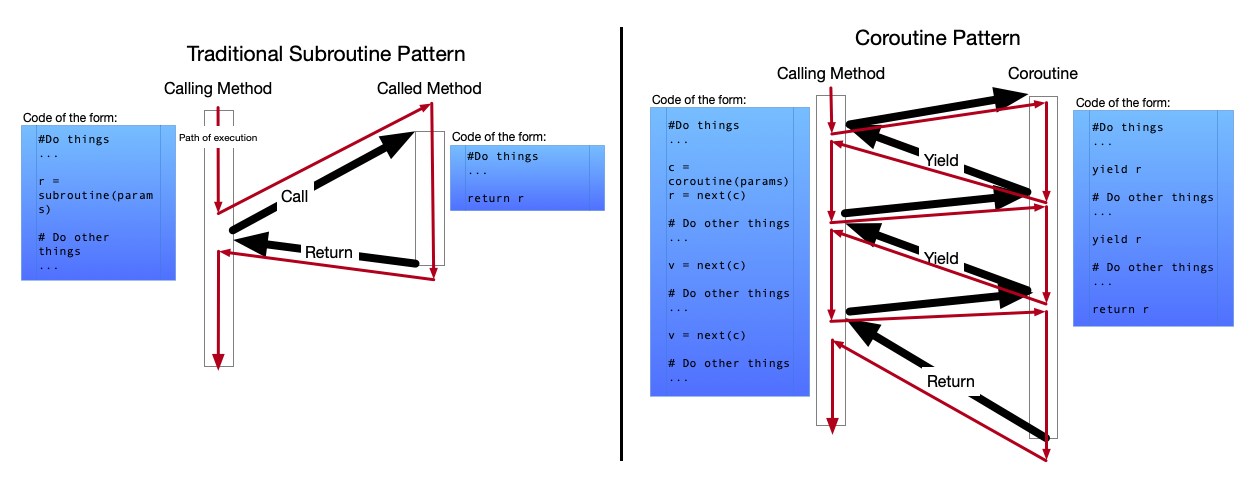
Python has had the capability to allow this execution model for some time in the form of Generators, but asyncio adds a new type of coroutine, which allows a natural way to write code where execution can move around between coroutines when the current one gets blocked.
A quick refresher on stacks and frames
Most operating systems and programming languages make use of an abstraction known as a “stack machine”. Unless you’ve done some very unusual low-level programming in assembler chances are all the programming you’ve ever done has made use of this abstraction. Its the mechanism which allows us to “call” one piece of code from another (amongst other things).
To illustrate this I’ll use a simple example piece of Python code:
def a_func(x):
return x-2
def main():
some_value = 12
some_other_value = a_func(some_value)
main()
When we begin execution of this code the stack is initialised as an empty Last In First Out area of storage in memory, and execution starts at the final line (main()).

Since this line is a function call the Python interpreter proceeds to apply the process for making a function call:
- It adds a new “frame” to the top of the stack. This is a data structure that can be thought of as containing anything that is put on the stack after it.
- It adds a “return pointer” to the top of the stack. This is an address that tells the interpreter where execution needs to resume from when the function returns.
- It moves execution so that the first line of the function is the next instruction to be executed.

Since the next instruction (some_value = 12) creates a local variable inside the context of the function call this variable is stored on the stack inside the stack frame for this function call.

The next instruction is some_other_value = a_func(some_value). Once again this is a function call, so the interpreter proceeds to apply the process for making a function call:
- It adds a new frame to the top of the stack.
- It adds a return pointer pointing to the next instruction to be called inside “main” to the top of the stack inside the frame.
- Since a parameter is being passed to the function it is placed on the top of the stack inside the frame.
- It moves execution so that the first line of the function “a_func” is the next instruction to be executed.

The next instruction to be executed is return x-2, so the interpreter performs the process for returning from a function.
- It removes the top frame from the stack, including everything in it.
- It places the return value of the function on the top of the stack.
- It moves execution to the instruction that the return pointer in the removed frame pointed to.

This pattern is followed by almost all code that it written in traditional programming languages. Multithreaded coding slightly alters this by having a separate stack per thread, but otherwise it’s pretty much exactly the same.
Asyncio, however, works a little differently.
Event Loops, Tasks, and Coroutines
In the asyncio world we no longer only have one stack per thread. Instead each thread has an object called an Event Loop. How to set up, work with, and shut down an event loop is covered in Part 2. For now just assume that one exists. The event loop contains within it a list of objects called Tasks. Each Task maintains a single stack, and its own execution pointer as well.

At any one time the event loop can only have one Task actually executing (the processor can still only do one thing at a time, after all), whilst the other tasks in the loop are all paused. The currently executing task will continue to execute exactly as if it were executing a function in a normal (synchronous) Python program, right up until it gets to a point where it would have to wait for something to happen before it can continue.
Then, instead of waiting, the code in the Task yields control. This means that it asks the event loop to pause the Task it is running in, and wake it up again at a future point once the thing it needs to wait for has happened.
The event loop can then select one of its other sleeping tasks to wake up and become the executing task instead. Or if none of them are able to awaken (because they’re all waiting for things to happen) then it can wait.
This way the CPU’s time can be shared between different tasks, all of which are executing code capable of yielding like this when they would otherwise wait.
IMPORTANT!: An event loop cannot forcibly interrupt a coroutine that is currently executing. A coroutine that is executing will continue executing until it yields control. The event loop serves to select which coroutine to schedule next, and keeps track of which coroutines are blocked and unable to execute until some IO has completed, but it only does these things when no coroutine is currently executing.
This execution pattern, where code control moves back and forth between different tasks, waking them back up at the point where they left off each time is called “coroutine calling”, and this is what asyncio provides to Python programming, as a means to ensure that CPUs sit idle less of the time.
So how does this work in Python?
This is all very good and nice as an abstract and generic discussion on the models behind asyncio, but I’ve got almost to the end of this first post in the series and I haven’t included a single piece of code that actually uses asyncio!
This was intentional. The actual syntax for using this in Python, with a focus on the interfaces that are useful when developing code that uses asyncio (as opposed to those only useful when extending the asyncio library) will be the focus of the next part of this series: Python Asyncio Part 2 – Awaitables, Tasks, and Futures